Overview
Nipoppy docs are moving
Nipoppy is undergoing a major refactor to move from scripts to a command-line interface (CLI) and Python API. The new documentation website (work in progress) can be found at https://nipoppy.readthedocs.io/.
If you are using the (soon-to-be legacy) scripts from Nipoppy 0.1.0, this is still the correct place to be. But we encourage you to check out the new website!
What is Nipoppy?
Nipoppy is a lightweight framework for analyzing (neuro)imaging and clinical data. It is designed to help users do the following:
- Curate and organize data into a standard directory structure
- Run data processing pipelines in a semi-automated and reproducible way
- Track availability (including processing status, if applicable) of raw, tabular and derived data
- Extract imaging features from MRI derivatives data for downstream analysis
Example workflow
Given a dataset to process, a typical workflow with Nipoppy can look like this:
- Fork the Nipoppy template code repository, then clone it
- This repository contains scripts to run processing pipelines (and track their results) on BIDS data
- Standardize raw imaging data: convert raw DICOM files into the NIfTI format and organize the dataset according to the BIDS standard
- This requires some custom scripts, including the
heuristic.pyfile for HeuDiConv
- This requires some custom scripts, including the
- Run commonly-used image processing pipelines
- Nipoppy currently supports FreeSurfer, fMRIPrep, TractoFlow, and MRIQC out-of-the-box, but new pipelines can be added by the user if needed
- Organize demographic and clinical assessment data
- This will most likely involve some custom data wrangling, for example to combine clinical assessment scores into a single file
- Run tracker scripts to determine the availability of imaging (raw and/or processed) and/or tabular data
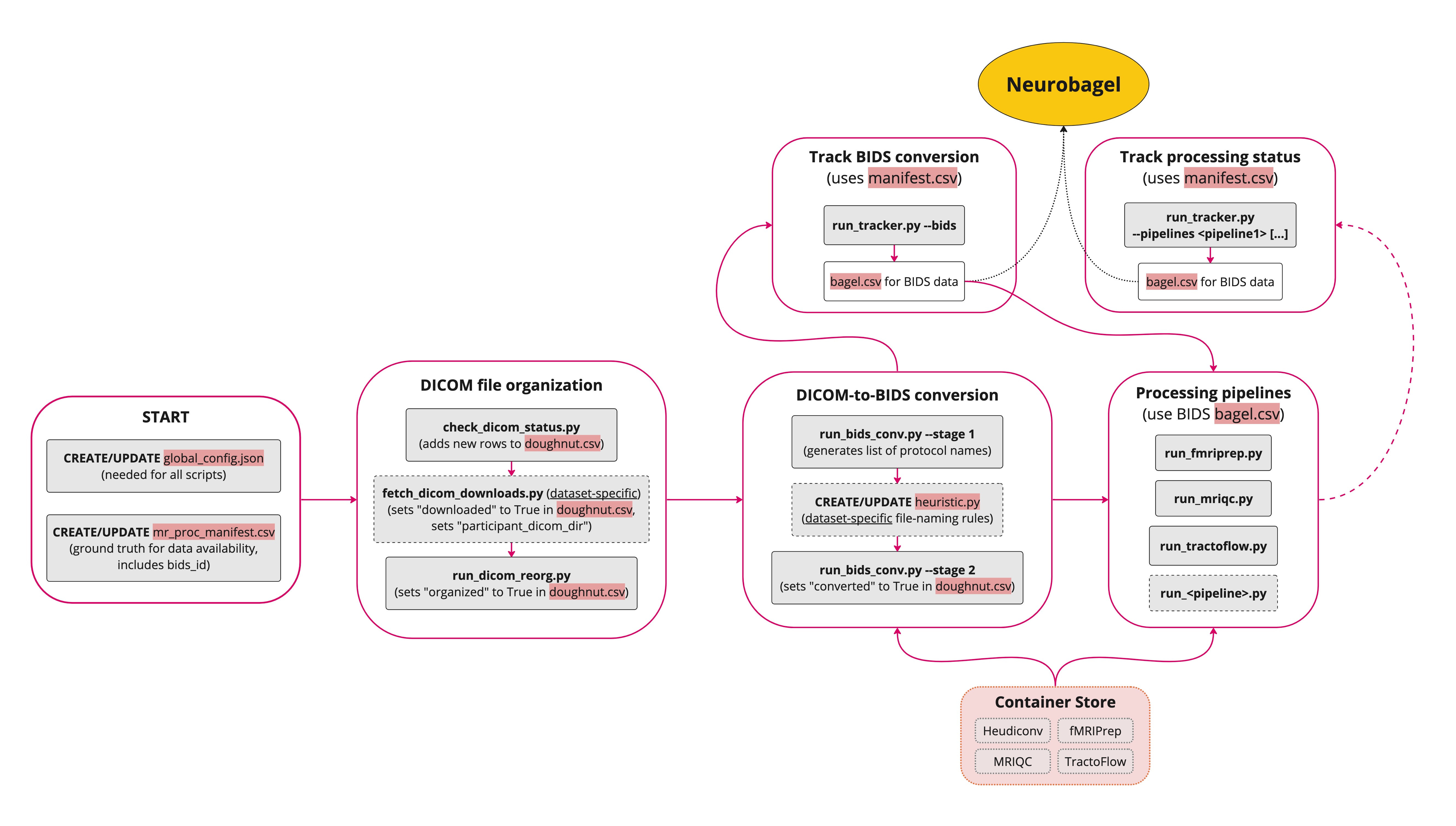
- We call these availability/status metadata files "bagels" because they can be ingested by Neurobagel for dashboarding and querying participants across multiple studies
Who is Nipoppy for?
Anyone who wants to process datasets with imaging data and/or use datasets processed with Nipoppy.
Data managers
- People who process datasets, either for specific analyses or to share with others
- Example use cases:
- Data curation
- Download/organize raw DICOM files
- Convert raw data to a BIDS directory structure
- Organize clinical data
- Data processing
- Run pre-existing processing pipelines
- Add scripts to run custom pipelines
- Do cross-dataset processing: running the same pipelines/versions on different datasets so that the outputs can be used together
- Data tracking
- Check processing failures and relaunch processing
- Generate bagel files for Neurobagel
- Data curation
Data users
- People who use tabular, derivative or other files produced by Nipoppy (e.g., from a shared Nipoppy-compliant dataset)
- Example use cases:
- Data querying
- Check availability of raw and/or derived data
- Check which pipelines and version have been run
- Data analysis
- Extract imaging features for downstream analyses from specific pipelines/versions
- Data querying
How does Nipoppy work?
Modules
Code: Codebase repo for running and tracking workflows- The codebase should start from the Nipoppy template repository. Additional custom scripts need to be added to process specific datasets.
Data: Dataset organized in a specific directory structure- This contains the data only and should not contain any code
Containers: Singularity/Apptainer containers encapsulating processing pipelines
Organization
Organization of Code, Data, and Container modules
Steps
The Nipoppy workflow steps and linked identifiers (i.e. participant_id, dicom_id, bids_id) are shown below:
FAQ
- Do I need to install anything to use Nipoppy?
- Nipoppy requires Python 3 and Apptainer/Singularity to work.
- Can Nipoppy process my entire dataset out-of-the-box?
- No: every dataset is different, and it is virtually impossible to have a workflow flexible enough to work with any dataset format or structure. However, once the imaging data is converted to a standard BIDS structure, running the image processing pipelines should be very straightforward.
- Do I need to follow all the steps listed in the example workflow?
- No: the purpose of the example workflow is to illustrate what can be done with Nipoppy, but you can choose to only use it for specific features (e.g., tracking).
- Can I run Nipoppy scripts in Windows/macOS?
- Nipoppy is designed to run on the Linux operating system, and will likely not work on other operating systems. This is mainly because it relies on Singularity, which cannot run natively on Windows or macOS. It is probably possible to use Nipoppy with Windows/macOS (e.g., using virtual machines), but we do not recommend it.
- Can I use Nipoppy on a cluster?
- Yes, as long as the cluster has Apptainer/Singularity installed
- Do I need to know how to use Apptainer/Singularity?
- The Nipoppy code repo contains scripts that call Singularity to run image processing pipelines. Users are not required to use Singularity directly, though we encourage users to learn about containers and/or Singularity if they are not familiar with these terms.
- I want to use Nipoppy with my own pipeline. Does it need to be containerized?
- Although we recommend the use of containers to facilitate reproducibility, it is not a strict requirement. You can run your own pipelines any way you want (on the BIDS data or even raw data), though the outputs should be organized in the same way as the other pipelines (fMRIPrep, TractoFlow, etc.) if you want to use the tracking features.
- What is Neurobagel and do I need to use it?
- Neurobagel is a data harmonization project that includes tools to perform cross-datasets searches for imaging data availability. You do not need Neurobagel for Nipoppy, though some Nipoppy outputs (specifically the
bageltracking files) can be used as input to some Neurobagel tools.
- Neurobagel is a data harmonization project that includes tools to perform cross-datasets searches for imaging data availability. You do not need Neurobagel for Nipoppy, though some Nipoppy outputs (specifically the
- How do I use the dashboard?
- Simply visit https://digest.neurobagel.org (no installation required). More information about the dashboard can be found here.